Introduction
In modern applications, databases play a critical role in ensuring seamless data management. Master-Slave Replication is a popular database replication strategy that helps improve performance and ensure data availability.
In this article, we will dive into the technical details of Master-Slave Replication, its use cases, and how it works.
Master-Slave Replication in Database
Master-Slave Replication is a database replication strategy in which one database server, the “master,” is responsible for receiving write operations while the other servers, known as “slaves,” are responsible for reading from the master server and updating their local copies.
This approach helps to distribute the load on the master database and ensures that read queries can be handled by slaves. It also helps to ensure data availability, as multiple copies of the data exist in different servers.
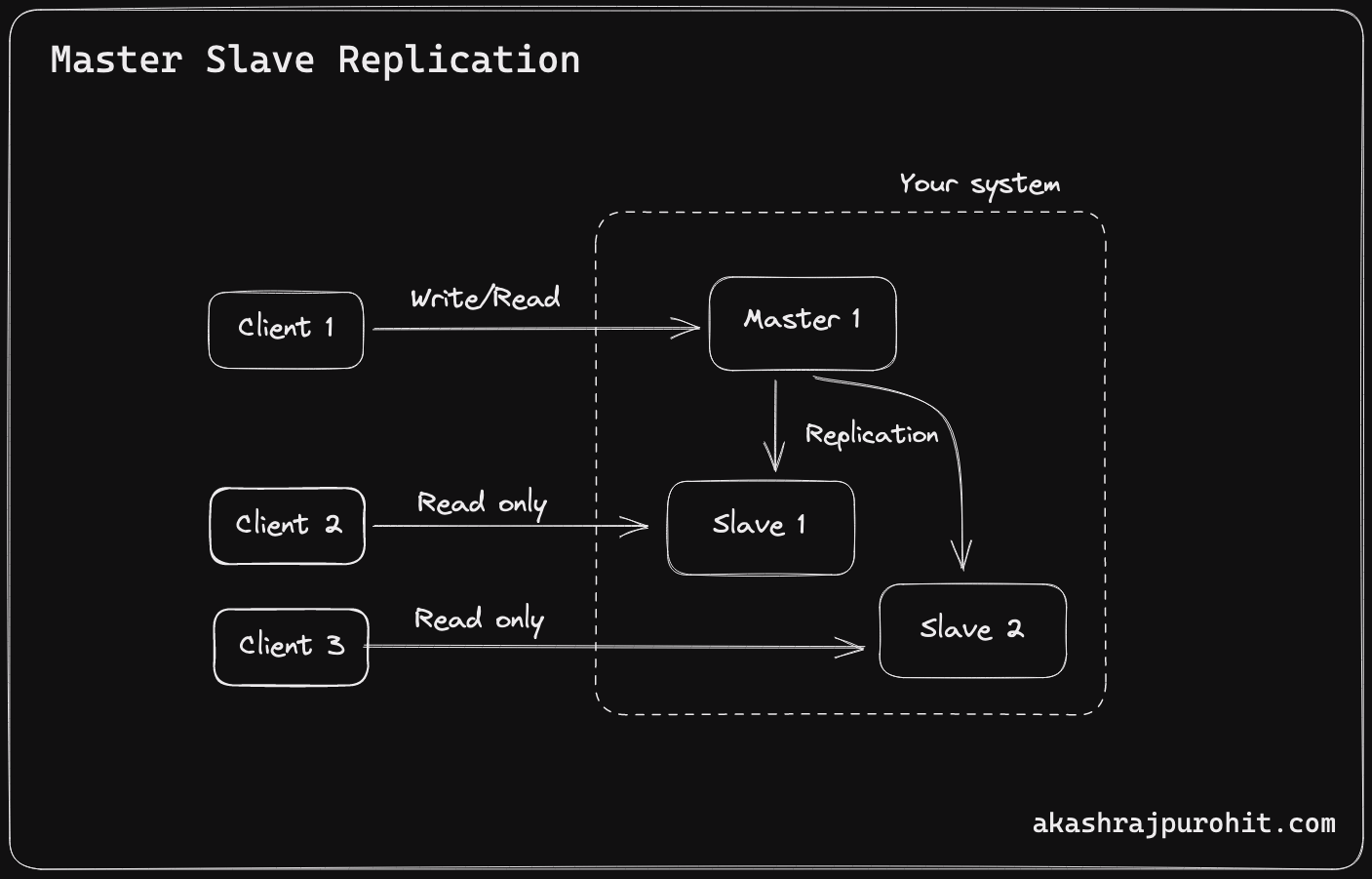
In Master-Slave Replication, the master server receives all the write requests and applies the changes to the database. These changes are then propagated to the slave servers asynchronously.
Slave servers maintain a log of all the changes made by the master server, and the log is used to update the local copy of the data. The slaves can serve read queries from the local copy of the data, thereby reducing the load on the master server.
One of the key benefits of Master-Slave Replication is improved performance. By distributing the read load across multiple slave servers, the master server can focus on handling write operations, which can be more resource-intensive.
The use of slaves to handle read queries also reduces the overall load on the system, which can improve performance for end-users.
Master-Slave Replication can also improve data availability. In the event of a failure of the master server, one of the slave servers can be promoted to take over the role of the master server.
This ensures that data is always available to end-users and that there is minimal disruption to service.
Real World Example
A popular example of Master-Slave Replication in action is in social media platforms such as Facebook and Instagram. These platforms generate a massive amount of data, which is constantly being written to the database.
In order to ensure that the system can handle the load, the data is distributed across multiple servers using Master-Slave Replication.
For instance, when a user uploads a photo to Facebook or Instagram, the write request is handled by the master server. The changes are then propagated to the slave servers, which maintain a local copy of the data.
When a user requests to view the photo, the read request is handled by one of the slave servers, which serves the data from the local copy. This approach helps to ensure that the system can handle the load and that data is always available to end-users.
Enjoying the content? Support my work! 💝
Your support helps me create more high-quality technical content. Check out my support page to find various ways to contribute, including affiliate links for services I personally use and recommend.
Conclusion
Master-Slave Replication is a powerful database replication strategy that helps improve performance and ensure data availability. By distributing the load across multiple servers, Master-Slave Replication can help to ensure that the system can handle high volumes of traffic and that data is always available to end-users.
With the rise of modern web applications and social media platforms, Master-Slave Replication has become an essential tool for ensuring the smooth operation of database systems.